PyTest 102¶
Fixtures¶
In essence, caching certain values to create DRY and faster tests.
Avoid long running set up functions like API and DB requests etc.
Definition¶
https://docs.pytest.org/en/stable/explanation/fixtures.html
Fixtures are requested by test functions or other fixtures by declaring them as argument names.
They are an example of dependency injection and replace the setup/teardown features of Unit Test.
Fixtures can thus use other fixtures. They are Python functions and can be the arguments of other functions.
Implementation¶
tests\02_py_coffee\02_fixtures\00_basic_fixtures\test_fixtures_0.py is an example:
@pytest.fixture
def initial_value():
return 5
def square(num) :
return num * num
# We pass in the fixture - dependency injection
def test_0240_FXT_square(initial_value):
result = square(initial_value)
assert result == initial_value**2
We can rename fixtures:
@pytest.fixture
def initial_value(name="custom_name"):
return 5
def test_0240_FXT_square(custom_name)
...
pytest --fixtures¶
pytest --fixtures is used to list available fixtures and where the fixture is located.
--fixtures-per-test¶
You can also use --fixtures-per-test to see what fixtures are used by each test and where the fixtures are de fined:
Yield and addfinalizer()¶
If one wants to set up and clean up resources, one can use the a generator function with yield.
One can also add def finalizer(): to a function and then use request.addfinalizer(finalizer) to register it:
# Generator function
@pytest.fixture()
def my_object_fixture():
print("Yielding fixture data...")
yield MyObjectThatRequiresCleanUp()
print("Do clean up after test has run...")
# add finalizer
@pytest.fixture
def setup_data(request):
# setup_data is now the fixture name we pass into our test...
print("\nSetting up resources...")
data = 22
# Define a finalizer function for teardown
def finalizer():
print("\nPerforming teardown...")
# Clean up any resources if needed
# Register the finalizer to ensure cleanup
request.addfinalizer(finalizer)
return data # Provide the data to the test
Scope¶
In essence, caching at the fixture level is the same as caching at the test level.
Function (Set up and tear down once for each test function) Class (Set up and tear down once for each test class) Module (Set up and tear down once for each test module/file) Session (Set up and tear down once for each test session i.e comprising one or more test files)
(There is also a PACKAGE scope but most literature does not mention this).
With fixture autouse, you can define a fixture that automatically runs before each test method, eliminating the need for manual fixture invocation in each test function.
This is especially useful when you have nested fixtures that need to be executed before each test function.
import pytest
# Define a fixture with a function scope i.e the instance is created for each test function
@pytest.fixture(scope="function")
def an_auto_use_fixture(static_number):
return "SOMETHING"
# no need to explicitly state the fixture an_auto_use_fixture
def test_001_convert_to_binary(number_converter):
print(an_auto_use_fixture)
...
def test_002_convert_to_binary(number_converter):
print(an_auto_use_fixture)
...
python -m pytest -vs .\tests\02_py_coffee\02_fixtures\00_basic_fixtures\test_fixtures_2.pyand change scope from module to function.
This can be confusing so I will suggest watching https://www.youtube.com/watch?v=mTMu8AtdG-E&list=PLxNPSjHT5qvuZ_JT1bknzrS8YqLiMjNpS&index=6 from CoffeeBeforeArch YT series for a better understanding.
We can see code examples in 02_py_coffee\02_fixtures\
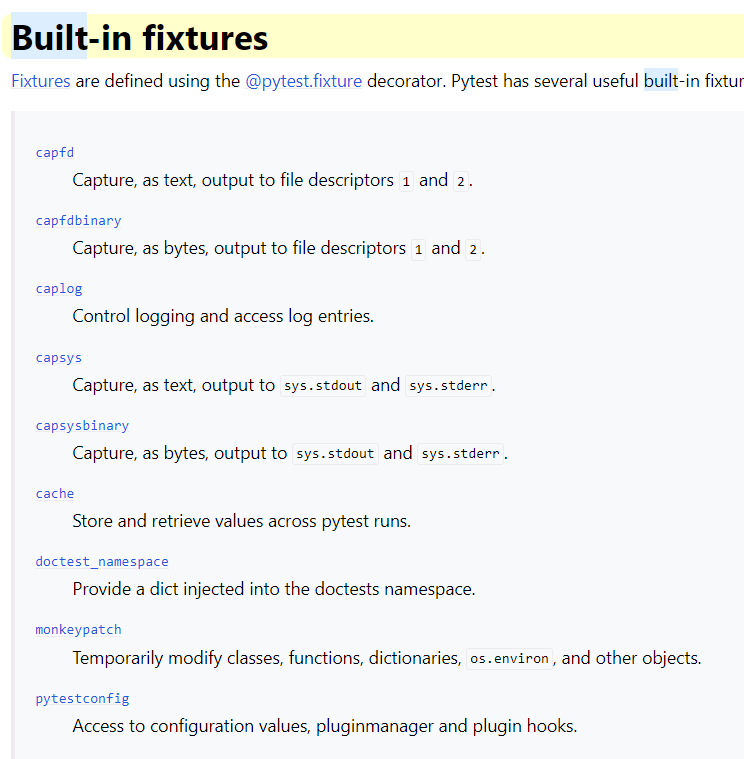
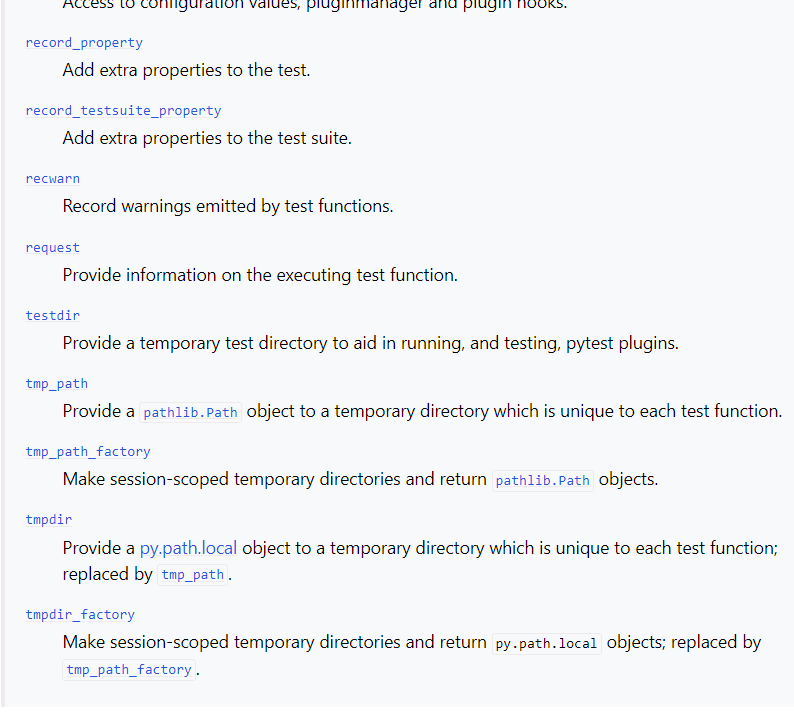
Built in fixtures¶
There are many built in fixtures provided by PyTest but I only use a few of them:
https://docs.pytest.org/en/stable/reference/fixtures.html#built-in-fixtures
Fixture availability is determined from the perspective of the test. A fixture is only available for tests to request if they are in the scope that fixture is defined in. If a fixture is defined inside a class, it can only be requested by tests inside that class. But if a fixture is defined inside the global scope of the module, then every test in that module, even if it’s defined inside a class, can request it.
Conftest¶
conftest.py is automatically discovered and registered by PyTest. It is a good place to store fixtures so that they can be reused in the folder it is located in and any subfolders.
It does not need to be imported.
If a fixture appears in many conftest.py files then the closest conftest.py file to the test is used.
Example is: python -m pytest -vs .\tests\02_py_coffee\02_fixtures\01_conftest\test_conftest_2\ demonstrating that the closest conftest.py fixture value is used.
Parametrization¶
We may want to run a test for a range of values, e.g, we may want to test our add() for a range of values.
Rather than do some Pythonic looping over a test, we can use the @pytest.mark.parametrize() to decorate the test and supply our values in this decorator.
A decorator is a function that wraps another function and any values passed into the deocrator are available to the inner function by the closure created.
Examples¶
python -m pytest tests/03_indian_pythonista/ip_04_parametrize/tests/test_sample.pypython -m pytest -vs -k TestClassSetUpin00_check_setup\test_01_setup::TestClassSetUp
n and expected are variable names that take values of supplied list
@pytest.mark.parametrize("n, expected", [(1, 2), (3, 4)])
class TestClass:
def test_simple_case(self, n, expected):
assert n + 1 == expected
def test_weird_simple_case(self, n, expected):
assert (n * 1) + 1 == expected
Output¶

Options¶
There are a great many options available:
- Add ids for more human readable output.
- Using the indirect=True parameter when parametrizing a test allows to parametrize a test with a fixture receiving the values before passing them to a test.
Customisation by hooks¶
Plugins¶
These are some of the most common plugins.
xdist aside, we can recreate some of the functionality through the use of hooks. The online course 'PyTest Cookbook - Using hooks to create plugins' that you will have a free coupon for will go through this in much more details.
It is easier than one might think!
pytest-csv¶
We already create our own cutomisable CSV output.
pytest-html¶
For a self-contained pytest-html report with css and images in one file:
python -m pytest --html=reports/report.html --self-contained-html -vs tests/00_check_setup
--self-contained means just one file and if we don't specify tests it will work on all test in the tests folder.
pytest-cov¶
Coverage is an important metric.
https://pytest-with-eric.com/coverage/poetry-test-coverage/ is a very good example with code to illustrate the use of pytest-cov.
We can run python -m pytest -vs tests\02_py_coffee --cov-report html --cov . to run tests on a particular folder. This produces a .coverage in the root of the folder and the report is index.html in the folder htmlcov.
Note how an XFAIL will result in less than 100% coverage. If we have if/else statements and we do not have tests for each case this will give coverage < 100%.
To create a report in the console, we can use python -m coverage report -m or coverage report -m.
To create an html report in htmlcov folder, we can use python -m coverage html and the report is index.html
We can omit tests using a .coveragerc file:
Some command line options:
--cov=src: Tells pytest-cov to measure coverage for the src folder.
--cov-report=term and --cov-report=html: Generate terminal and HTML coverage reports.
--cov-branch: Measures branch coverage as well as line coverage.
--cov-config=none: Specifies that no external config file will be read, but coverage will still run.
--cov-omit=src/legacy/*,src/migrations/*: Specifies the directories you want to omit from the coverage report.
100% code coverage? - https://edbennett.github.io/python-testing-ci/07-coverage/index.html
https://pytest-with-eric.com/coverage/python-coverage-omit-subfolder/ for more ways and deeper information.
pytest-random¶
Ideally, all tests are independent of each other and randomising the order should not change the results of the test.
Randomising tests are a good way to test this.
We create our own local plugin version in the Udemy Course and the pytest_collect_modifyitems is a hook that can be used for filtering, ordering and randomising:
# A pytest hook to for modifying collected items
def pytest_collection_modifyitems(items, config):
# we can sort order of items (tests) as needed
# can be used to sort by fixtures used if one is say expensive in time
# items.sort(key=lambda item: "expensive" in item.fixturenames)
random.shuffle(items)a
return items
We can filter and order tests:
# Deselecting/skipping tests based on certain criteria
def pytest_collection_modifyitems(items, config):
selected = []
deselected = []
for test in items:
if "custom_expensive_marker" in all_markers:
deselected.append(test)
else:
selected.append(test)
# Update the deselected tests
config.hook.pytest_deselected(items=deselected)
# Update the selected tests
items[:] = selected
pytest-xdist¶
Using python -m pytest -vs .\tests\00_check_setup\Xtest_09_xdist.py -n auto with there being 4 tests in this test file, the overhead to set up 4 workers is around 2 seconds.
auto will detect number of cores. One can set number of cores -n 4 for example.
This is one of the most effective ways to speed up test along with using fixtures to 'cache' values if they are long running.
The file has X at beginning to avoid being called when we do a general pytest run as this would slow things down.
This does show how we can call any file for a test run. We just need test_ etc if we want PyTest to discover the tests.
!!!By running separate workers, we will get multiple CSV outputs. If you are processing them, you will need to batch them accordingly as they wille ach contain the tests they run. Some tests, if dependent on others may fail if they are in a different thread. Dependent tests are an anti-pattern anyway. Better to log directly to the database. See https://pytest-cookbook.com/pytest/pytest_full_stack_customise/ on how to do this.
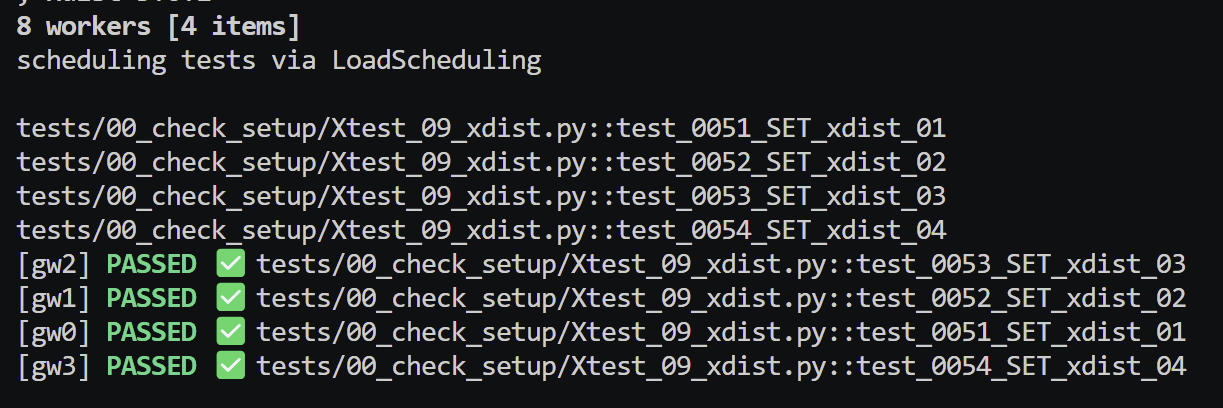
Running with n=1, the test took around 21s. Running with n=4, the test took around 8s. Running with n=8, the test took around 9s as there is overhead with managing workers.
There are plugins which can split tests based on execution time based on previous runs.
https://pypi.org/project/pytest-split/
https://pypi.org/project/pytest-split-tests/